Read Json File From S3 Using Lambda in Python
Introduction to AWS Lambda, Layers and boto3 using Python3
A serverless approach for Data Scientists
![]()
Amazon Lambda is probably the nearly famous serverless service available today offer low cost and practically no cloud infrastructure governance needed. It offers a relatively simple and straightforward platform for implementing functions on unlike languages like Python, Node.js, Coffee, C# and many more.
Amazon Lambda can exist tested through the AWS panel or AW S Command Line Interface. One of the main problems near Lambda is that it becomes tricky to set up every bit shortly as your functions and triggers get more than complex. The goal of this commodity is to present you a digestible tutorial for configuring your offset Amazon Lambda part with external libraries and doing something more useful than only printing "Hullo earth!".
We are going to apply Python3, boto3 and a few more libraries loaded in Lambda Layers to help us attain our goal to load a CSV file equally a Pandas dataframe, do some data wrangling, and salvage the metrics and plots on study files on an S3 bucket. Although using the AWS console for configuring your services is not the best practice approach to work on the cloud, we are going to show each footstep using the console, because information technology's more convenient for beginners to empathize the basic structure of Amazon Lambda. I'm sure that later going through this tutorial you'll have a practiced thought on migrating part of your local data analysis pipelines to Amazon Lambda.
Setting our environment
Before nosotros start messing around with Amazon Lambda, we should first ready our working environs. We first create a folder for the project (1) and the environment Python 3.7 using conda (you tin also use pipenv )(two). Next, nosotros create two folders, one to save the python scripts of your Lambda function, and one to build your Lambda Layers (3). Nosotros'll explain better what Lambda Layers consists later on the article. Finally, we tin create the binder construction to build Lambda Layers so it can exist identified by the Amazon Lambda (four). The folder structure we created is going to help you lot better understand the concept behind Amazon Lambda and also organize your functions and libraries.
# 1) Create project folder
mkdir medium-lambda-tutorial # Modify directory
cd medium-lambda-tutorial/ # 2) Create environment using conda
conda create --name lambda-tutorial python=three.seven
conda actuate lambda-tutorial # 3) Create one folder for the layers and another for the
# lambda_function itself
mkdir lambda_function lambda_layers # iv) Create the folder structure to build your lambda layer
mkdir -p lambda_layers/python/lib/python3.7/site-packages
tree .
├── lambda_function
└── lambda_layers
└── python
└── lib
└── python3.seven
└── site-packages
Amazon Lambda Bones Structure
1 of the main troubles I encountered when trying to implement my kickoff Lambda functions was trying to understand the file construction used past AWS to invoke scripts and load libraries. If y'all follow the default options 'Writer from scratch' (Figure 1) for creating a Lambda function, y'all'll end upwardly with a binder with the name of your role and Python script named lambda_function.py inside it.
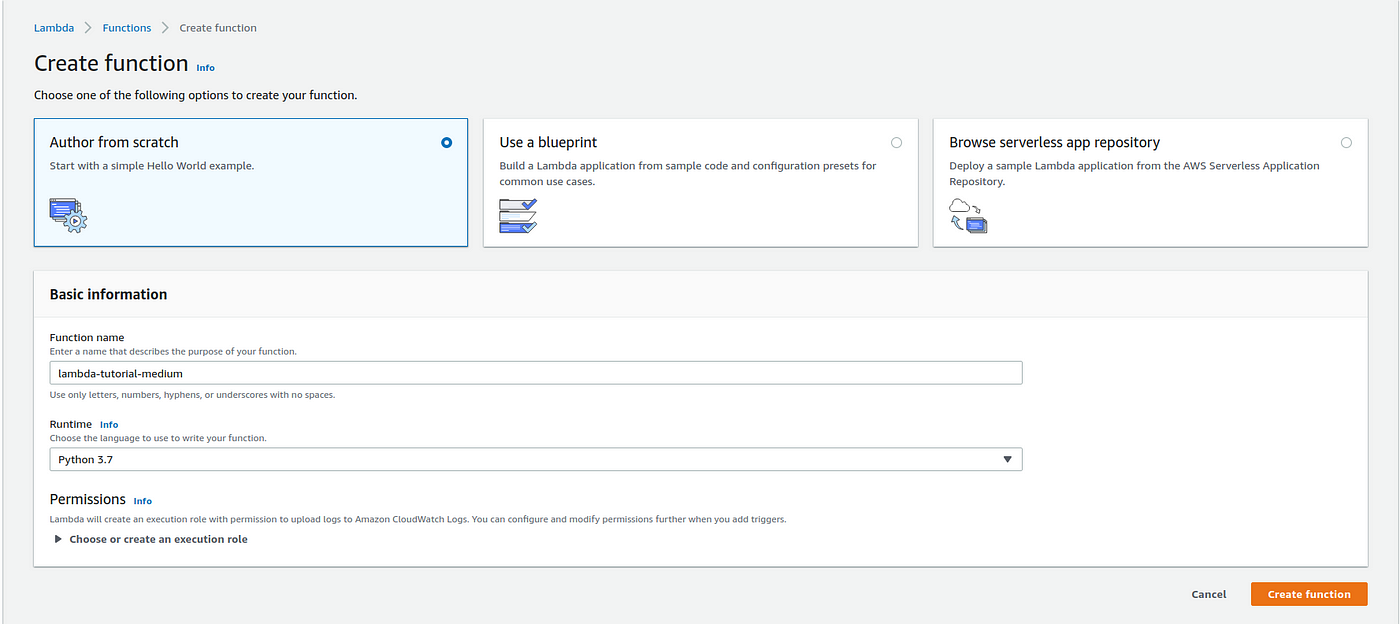
The lambda_function.py file has a very simple construction and the code is the post-obit:
import json def lambda_handler(event, context):
# TODO implement
render {
'statusCode': 200,
'torso': json.dumps('Hello from Lambda!')
}
These 8 lines of code are key to understanding Amazon Lambda, so we are going through each line to explicate information technology.
-
import json: You can import Python modules to use on your function and AWS provides you with a listing of available Python libraries already built on Amazon Lambda, similarjsonand many more. The trouble starts when you need libraries that are non bachelor (we volition solve this problem afterward using Lambda Layers). -
def lambda_handler(event, context):This is the chief function your Amazon Lambda is going to call when you run the service. It has two parameterseventandcontext. The get-go one is used to pass data that can be used on the function itself (more on this afterward), and the 2d is used to provide runtime and metadata information. -
# TODO implementHere is where the magic happens! Yous can use the torso of thelambda_handlerfunction to implement any Python code you want. -
renderThis part of the role is going to return a default lexicon withstatusCodeequal to 200, andbodywith a "Hello from Lambda". Yous tin can alter this return later to any Python object that suits your needs.
Before running our outset test, it's important to explicate a key topic related to Amazon Lambda: Triggers. Triggers are basically means in which you invoke your Lambda function. There are many ways for you to prepare up your trigger using events like adding a file to a S3 bucket, changing a value on a DynamoDB tabular array or using an HTTP request through Amazon API Gateway. You tin pretty much integrate your Lambda part to exist invoked by a wide range of AWS services and this is probably 1 of the advantages offered by Lambda. One mode we can do it to integrate with your Python lawmaking is by using boto3 to phone call your Lambda function, and that's the approach nosotros are going to use after on this tutorial.
Every bit you can see, the template structure offered past AWS is super simple, and you tin can test it by configuring a test consequence and running it (Figure ii).
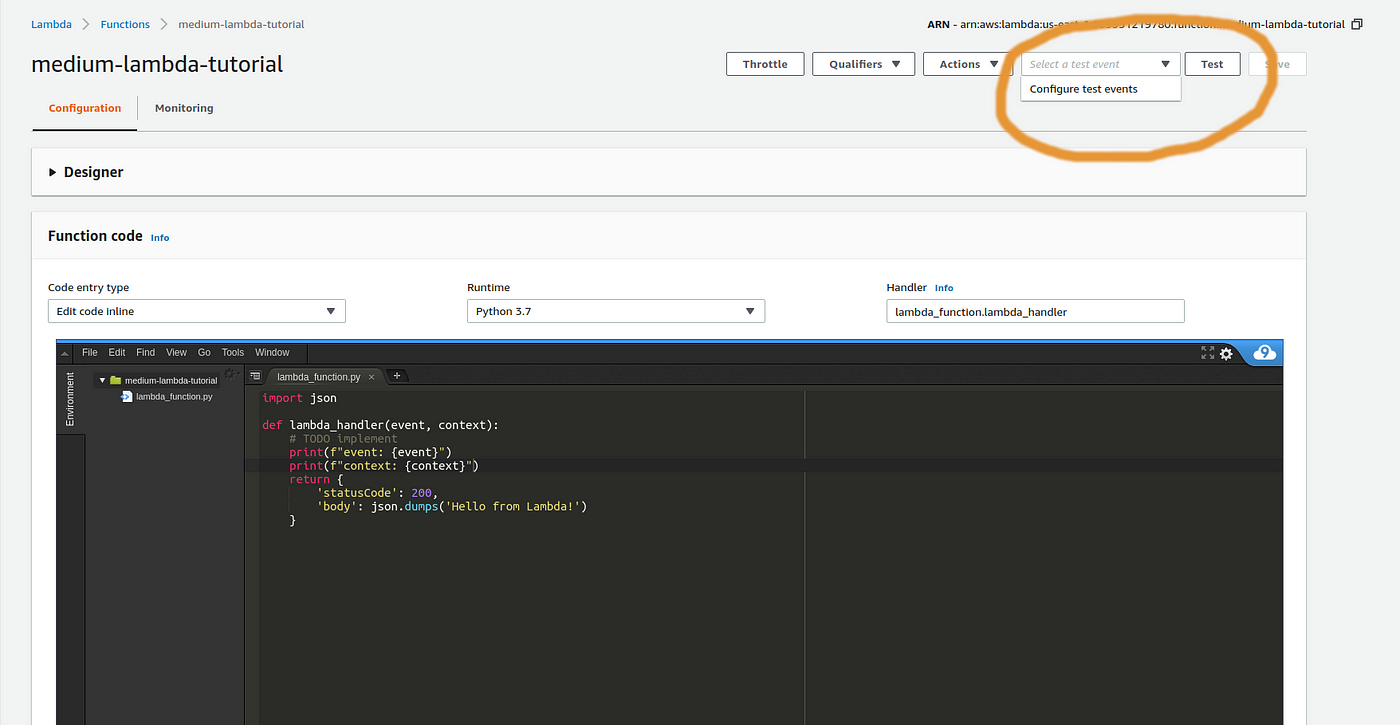
As we didn't alter annihilation on the code of the Lambda Function, the test runs the process and nosotros receive a green alarm describing the successful event (Figure iii).
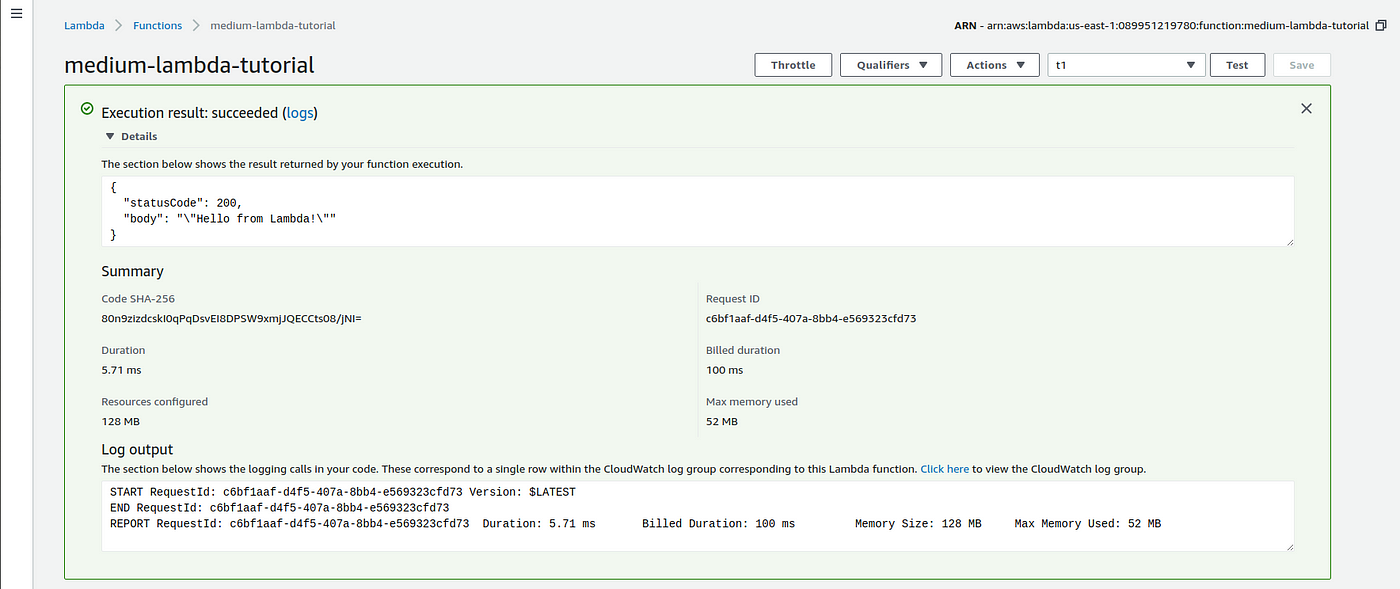
Figure iii illustrates the layout of the Lambda invocation result. On the upper part y'all tin can see the dictionary independent on the returned statement. Underneath in that location is the Summary part, where we can come across some important metrics related to the Lambda Role like Request ID, duration of the function, the billing duration and the corporeality of memory configured and used. We won't go deep on Amazon Lambda pricing, just it is of import to know that is charged based on:
- duration the function is running (rounded upwards to the nearest 100ms)
- the amount of retentiveness/CPU used
- the number of requests (how many times yous invoke your function)
- amount of data transferred in and out of Lambda
In general, it is actually inexpensive to test and apply it, so yous probably won't have billing problems when using Amazon Lambda for minor workloads.
Another of import detail related to the pricing and performance is how CPU and memory are available. You choose the amount of retention for running your function and "Lambda allocates CPU ability linearly in proportion to the amount of retentivity configured".
At the bottom of Figure 3, you lot tin can see the Log output session where you can cheque all the execution lines printed by your Lambda office. 1 swell characteristic implemented on Amazon Lambda is that it is integrated with Amazon CloudWatch, where y'all can notice all the logs generated past your Lambda functions. For more details on monitoring execution and logs, please refer to Casey Dunham swell Lambda Article.
We have covered the basic features of Amazon Lambda, so on the next sessions, nosotros are going to increase the complexity of our job to show you a real-earth employ providing a few insights into how to run a serverless service on a daily footing.
Calculation layers, expanding possibilities
One of the great things virtually using Python is the availability of a huge number of libraries that helps you implement fast solutions without having to lawmaking all classes and functions from scratch. As mentioned before, Amazon Lambda offers a list of Python libraries that you tin can import into your office. The trouble starts when you accept to employ libraries that are not available. 1 way to exercise it is to install the library locally inside the same folder you have your lambda_function.py file, zip the files and upload it to your Amazon Lambda panel. This process can be a laborious and inconvenient task to install libraries locally and upload it every time y'all take to create a new Lambda part. To make your life easier, Amazon offers the possibility for us to upload our libraries as Lambda Layers, which consists of a file structure where you store your libraries, load it independently to Amazon Lambda, and use them on your lawmaking whenever needed. In one case yous create a Lambda Layer it can be used by any other new Lambda Office.
Going dorsum to the first session where we organized our working environment, we are going to utilize the folder structure created inside lambda_layer binder to install locally 1 Python library, Pandas.
# Our current binder structure
.
├── lambda_function
└── lambda_layers
└── python
└── lib
└── python3.7
└── site-packages # 1) Pip install Pandas and Matplotlib locally
pip install pandas -t lambda_layers/python/lib/python3.seven/site-packages/. # 2) Nil the lambda_layers folder
cd lambda_layers
null -r pandas_lambda_layer.zip *
By using pip with parameter -t nosotros tin can specify where we want to install the libraries on our local folder (ane). Next, nosotros just demand to aught the folder containing the libraries (ii) and we have a file ready to exist deployed equally a Layer. Information technology's important that you keep the construction of folders nosotros create on the beginning (python/lib/python3.7/site-packages/) and then that Amazon Layer can identify the libraries contained on your zipped package. Click on the option Layers on the left console of your AWS Lambda console, and on the button 'Create Layer' to outset a new one. Then nosotros tin specify the proper name, description and uniform runtimes (in our instance is Python three.7). Finally, we upload our zipped folder and create the Layer (Figure iv).
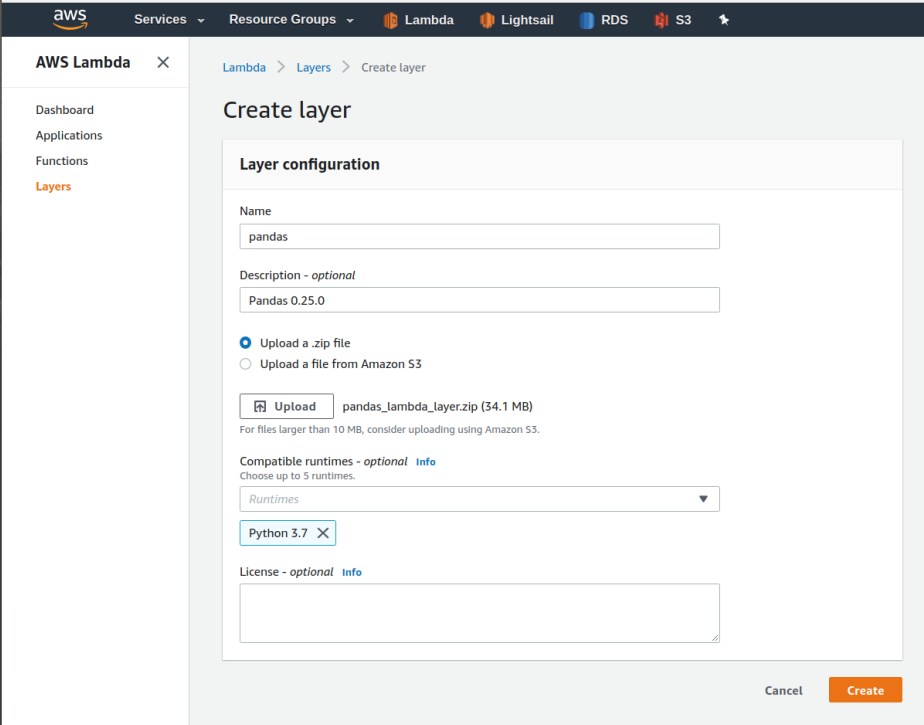
It takes less than a minute and we accept our Amazon Layer ready to exist used on our code. Going back to the console of our Lambda part we can specify which Layers we are going to apply by clicking on the Layer icon, and then on 'Add together a layer' (Effigy 5).
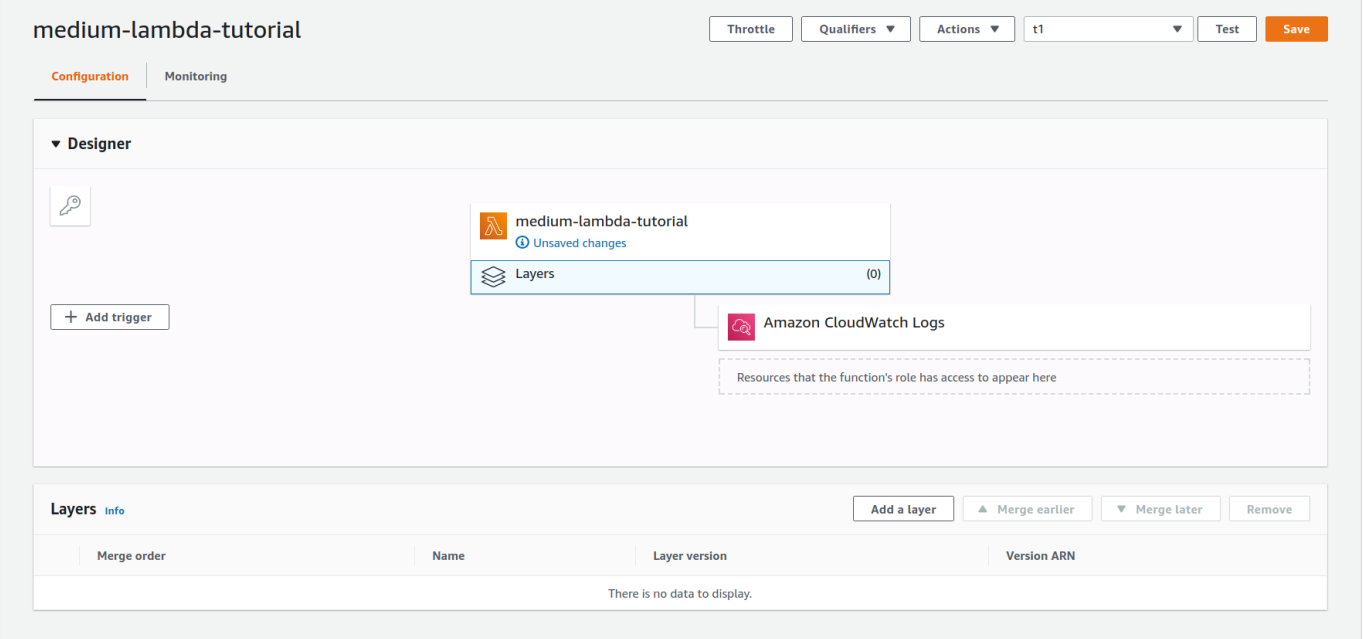
Adjacent, we select the Layer we just created and its corresponding version (Figure 6). As you can come across from Figure half-dozen, AWS offers a Lambda Layer with Scipy and Numpy ready to be used, and then yous don't need to create new layers if the only libraries yous need are one of these two.
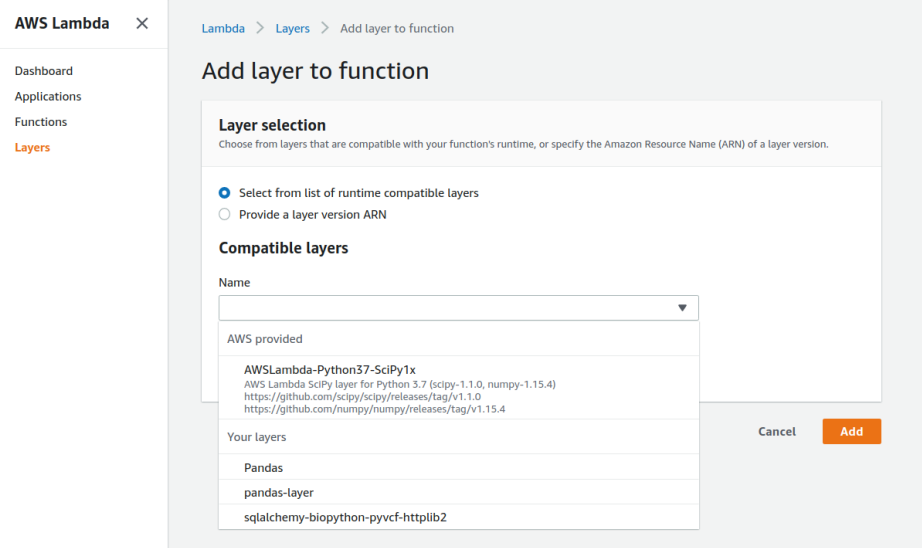
After selecting our Pandas Layer all we need to do is import it on your Lambda code as it was an installed library.
Finally, let'southward beginning coding!
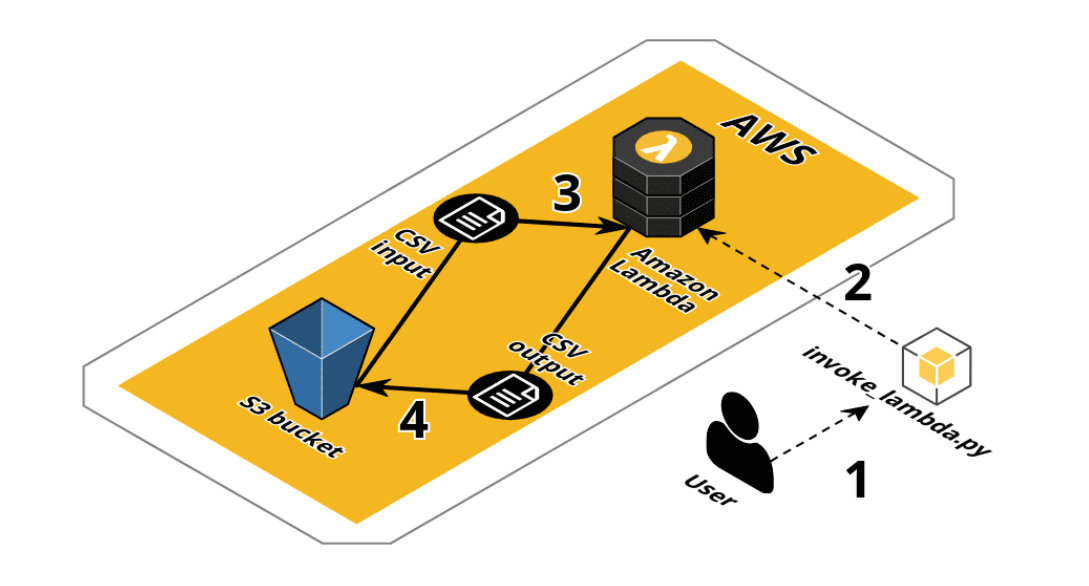
Now that we take our environment and our Pandas Layer gear up, we can starting time working on our lawmaking. As mentioned earlier, our goal is to create a Python3 local script (1) that can invoke a Lambda role using defined parameters (2) to perform a simple data analysis using Pandas on a CSV located on a S3 (3) and save the results back to the same saucepan (4) (Figure vii).
To requite Amazon Lambda access to our S3 buckets we can simply add a role to our function by going to the session Execution role on your console. Although AWS offers you some function templates, my advise is to create a new function on the IAM console to specify exactly the permission need for your Lambda role (Left panel on Effigy 8).
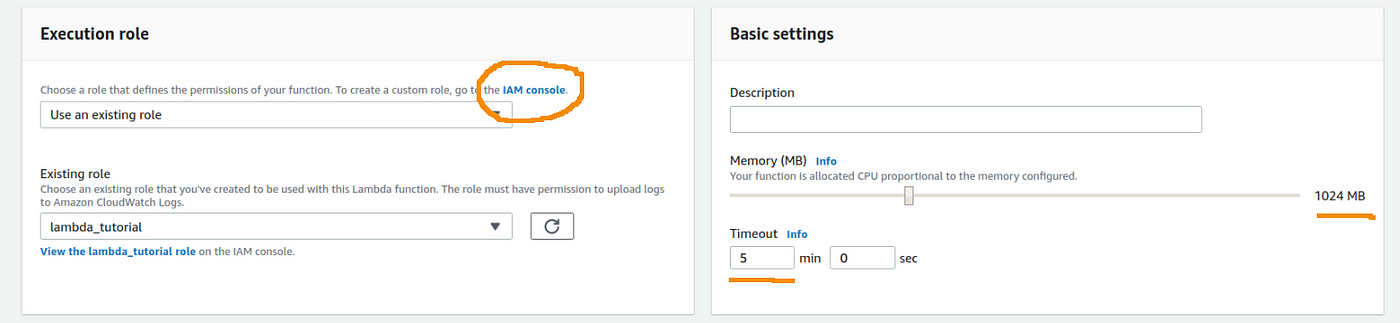
We also changed the amount of retentiveness available from 128MB to 1024MB, and the timeout to 5 minutes instead of just 3 seconds (Correct console on figure 8), to avoid running out of retentivity and timeout error. Amazon Lambda limits the full corporeality of RAM retentiveness to 3GB and timeout to 15 minutes. So if you need to perform highly intensive tasks, you might detect issues. One solution is to concatenation multiple Lambdas to other AWS services to perform steps of an assay pipeline. Our thought is not to provide an exhaustive introduction to Amazon Lambda, so if you want to know more well-nigh it, please check out this article from Yi Ai.
Before showing the lawmaking, it's important to describe the dataset nosotros are going to utilize on our modest project. I chose the Fifa19 player dataset from Kaggle, which is a CSV file describing all the skills from the players present on the game (Tabular array ane). It has 18.207 rows and 88 columns and you can become information well-nigh the nationality, clubs, bacon, skill level and many more characteristic from each role player. Nosotros downloaded the CSV file and uploaded it to our S3 bucket (renamed it fifa19_kaggle.csv).
So now we can focus on our code!
As we can come across in the script above, the first 5 lines are just importing libraries. With exception to Pandas, all the other libraries are available for use, without having to use Layers.
Next, we have an accessory function called write_dataframe_to_csv_on_s3 (lines 8 to 22) used to relieve a Pandas Dataframe to a specific S3 bucket. We are going to apply information technology to save our output Dataframe created during the analysis.
The other function nosotros have on our code is the chief lambda_handler,the 1 that is going to be called when nosotros invoke the Lambda. We can encounter that the get-go 5 assignments on lambda_handler (lines 28 to 32) are variables passed to the resultobject.
From the lines 35 to 41 we use boto3 to download the CSV file on the S3 saucepan and load information technology as a Pandas Dataframe.
Next, on line 44 we use the grouping by method on the Dataframe to aggregate the Grouping cavalcade and get the mean of the Column variable.
Finally, we employ the function write_dataframe_to_csv_on_s3 to save df_groupby on the specified S3 bucket, and render a dictionary with statusCode and body every bit keys.
As described before in the Amazon Lambda Basic Structure session, the consequence parameter is an object that carries variables bachelor to lambda_handler function and nosotros can define these variables when configuring the examination event (Figure ix).
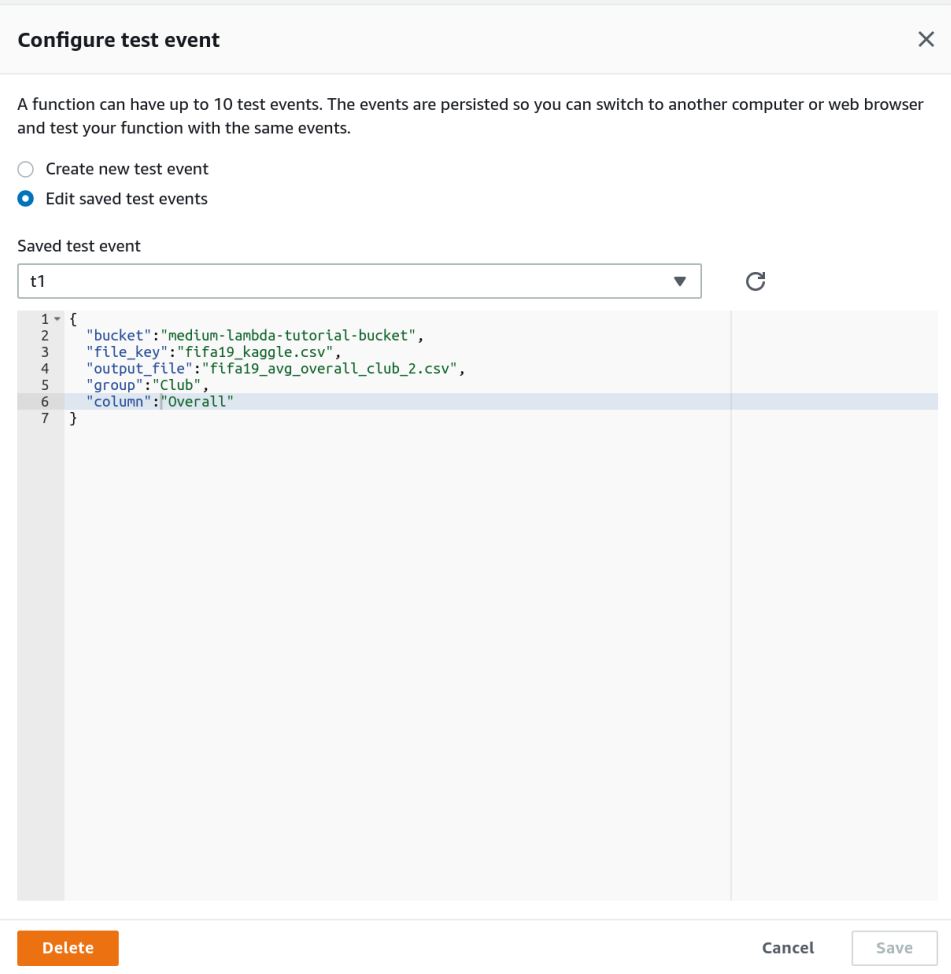
If we run this the test, using the right values related to the 5 keys of test JSON, our Lambda function should process the CSV file from S3 and write downwards the resulted CSV dorsum to the saucepan.
Although using the variables hardcoded on examination outcome can evidence the concept of our Lambda code, it's not a applied mode to invoke the role. In order to solve it, nosotros are going to create a Python script (invoke_lambda.py) to invoke our Lambda function using boto3.
We are going to utilize only three libraries: boto3, json and sys. From lines v to x nosotros utilise sys.argv to access the parameter when running the script through the command line.
python3 invoke_lambda.py <saucepan> <csv_file> <output_file> <groupby_column> <avg_column> <aws_credentials> The last parameter (aws_credentials) nosotros provide to invoke_lambda.py is a JSON file with our credentials to access AWS services. You may configure your credentials past using the awscli or generate a hole-and-corner cardinal using IAM.
On our main function, invoke_lambda we utilize boto3 customer to define admission to Amazon Lambda (line 38). The side by side object called payload is a dictionary with all the variables nosotros want to use inside our Lambda function. These are the Lambda variables that tin be accessed using the event.get('variable').
Finally, we only call client.invoke() with the target Lambda function proper noun, Invocation blazon, and payload conveying the variables (line 54). The Invocation type tin can be of three types: RequestResponse (default), to"invoke the function synchronously. Keep the connexion open until the office returns a response or times out"; Consequence, to asynchronously call Lambda; or DryRun when you need to validate user information. For our master purpose, we are going to apply the default RequestResponse option to invoke our Lambda, as it waits for the Lambda process to return a response. Every bit we defined a try/except structure on our Lambda Role, if the process runs without errors, it would return a status code 200 with the bulletin "Success!", otherwise it would render status code 400 and the message "Error, bad asking!".
Our local script invoke_lambda.pywhen run with the right parameters takes a few seconds to return a response. If the response is positive with condition code 200, you might check your S3 bucket to search for the report file generated by the Lambda role (Table 2). As we used the columns "Society" to group past and "Overall" to get the mean, we are showing the 20 clubs with the highest average player overall skill level.
Concluding considerations
I hope this quick introduction (not so quick!) to Amazon Lambda helped y'all sympathise better the basics and bolts of this serverless service. And that it can aid you somehow try different approaches on your Data Science projects. For more information virtually serverless compages using AWS please bank check this great commodity from Eduardo Romero.
And if you experience you need a deeper agreement of AWS Lambda, I recently published an article that describes the infrastructure backside Lambda and a few other functionalities for it.
Thanks a lot for reading my article!
- Yous tin can discover my other articles on my profile page 🔬
- If yous enjoyed it and want to get Medium a member you can use my referral link to also back up me 👍
Source: https://towardsdatascience.com/introduction-to-amazon-lambda-layers-and-boto3-using-python3-39bd390add17
0 Response to "Read Json File From S3 Using Lambda in Python"
Post a Comment